
Wprowadzenie:
W związku z rosnącą popularnością platform chmurowych, takich jak Google, AWS i Azure, postanowiliśmy stworzyć serię artykułów, w których omówimy podstawowe funkcjonalności tych środowisk na konkretnych przykładach użycia.
Zacznijmy od Google oraz jednego z bardziej dojrzałych i użytecznych komponentów, czyli BigQuery. Będziemy również wykorzystywać Google Cloud Storage jako podstawowe miejsce przechowywania danych przetwarzanych w BigQuery.
Podstawowe rzeczy, które chcielibyśmy zweryfikować w tym artykule:
- jak trudno jest utworzyć proste środowisko, pozwalające procesować pliki CDR (struktura opisana poniżej) z 100 mln rekordów,
- jaki jest koszt platformy używanej w trakcie naszego testu,
- jaka jest wydajność platformy
Use Case:
Jako przykład użycia wybraliśmy przetwarzanie plików zwanych CDR, czyli call detail record, są to pliki często wykorzystywane w branży telekomunikacyjnej. Ich formaty mogą być najróżniejsze, nie ma też jednego przyjętego standardu. Na potrzeby tego przykładu przygotowaliśmy następujący format plików:
Id INT, CustomerId INT, DestinationPhone INT, CallDate DATE, CallTime STRING, Duration INT, Network STRING, Location STRING, NetAmount NUMBER, Amount NUMBER – NetAmount i Amount są przechowywane w pliku źródłowym jako INT, jednak odpowiadają liczbie o precyzji 2 miejsc po przecinku, np. 101 oznacza 1.01.
Przykładowe dane:

Przeprowadzimy na nich proste agregacje w celu sprawdzenia wydajności środowiska i oszacowania złożoności wdrożenia nowej platformy.
Komponent Google BigQuery jest chmurową, komercyjną implementacją narzędzia znanego wcześniej jako Dremel. Google zaprojektował je z myślą o przetwarzaniu dużych zbiorów danych w rozproszonym środowisku (podobnie jak Apache Hadoop) – Dremel wykorzystuje dwa podstawowe założenia architekturalne, (a) Columnar Storage (b) Tree Architecture – czyli wielowarstwowa struktura serwerów. Połączenie tych założeń oraz skali – kilka tysiecy serwerów działających równocześnie – BigQuery jest w stanie z dużą wydajnością przetwarzać PB danych. Na dodatek Google zadbało o odpowiednią wycenę środowiska, dostawca pobiera opłatę za ilość przechowywanych i transferowanych GB. Czyli w przypadku, kiedy zbiory nie są duże oraz wykorzystujemy je tylko w określony, przewidywalny sposób – BigQuery okazuje się dużo tańszym rozwiązaniem niż inne bazy danych, bez konieczności utrzymania skomplikowanej infrastruktury. W kolejnych artykułach będziemy porównywać to rozwiązanie do konkurencji oraz do klastra Apache Hadoop, który zbudowaliśmy na platformie DigitalOcean.
Pierwsze kroki:
Aby zacząć naszą przygodę z Google BigQuery, potrzebujemy mieć założone konto Google – nie ma tutaj większego znaczenia, czy jest to konto indywidualne czy korporacyjne. Logujemy się na Google Cloud Console – Google oferuje „free trial” w postaci 300$ w prezencie na 12 miesięcy.

Aby móc komercyjnie wykorzystywać możliwości tej platformy, należy w zakładce po lewej stronie wybrać Billing i przejść przez Wizard, uzupełniając nasze dane (dane firmy, jeśli chcemy otrzymywać faktury, dane karty kredytowej).
Po ich uzupełnieniu możemy przejść do korzystania z platformy, mamy już założony swój inicjalny projekt. W ramach niego będziemy tworzyć zasoby, np. dyski, serwery, a także korzystać z usług, takich jak BigQuery. Koncepcja kilku projektów w ramach jednego konta, pozwala na podejmowanie różnych inicjatyw/działań równocześnie.
Google Cloud Storage (GCS):
W celu skorzystania z możliwości BigQuery zakładamy Bucket w usłudze Google Cloud Storage. Bucket jest naszym odpowiednikiem macierzy dyskowej wykorzystywanej przez znaczną większość usług Google. Fizycznie Cloud Storage odpowiada architekturze HDFS (Apache Hadoop), czy Blob Storage (Azure). Zapewnia dystrybucję danych w ramach rozproszonego środowiska, pokrywając jednocześnie potrzeby bezpieczeństwa czy wydajności. W celu utworzenia Bucket-u należy z lewego menu wybrać Storage->Browse.
Wybieramy Create bucket:
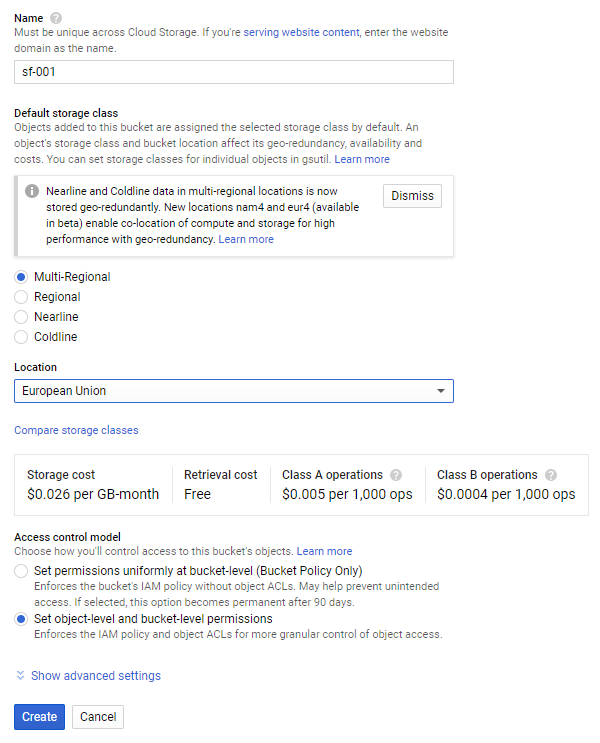
W następnym kroku określamy takie atrybuty, jak unikalną nazwę, lokalizację danych oraz nadajemy uprawnienia do zasobów:
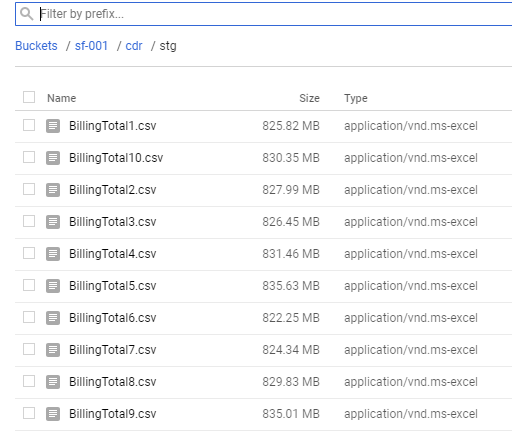
Po wygenerowaniu Bucket-u tworzymy katalogi, najpierw cdr, następnie stg. Posłużą nam one do umieszczenia danych wejściowych z plikami cdr. Dane testowe to zbiór 10 plików CSV, każdy o rozmiarze około 800 MB – cały zbiór to niemal 8 GB – liczba rekordów to ponad 100 mln.
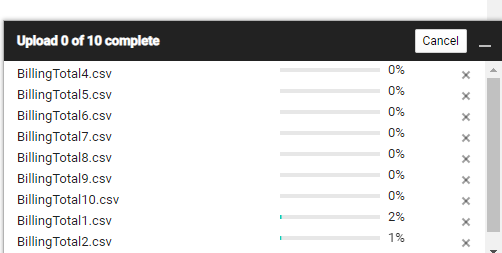
Za pomocą przycisku Upload files dodajemy dane do naszego bucketu w lokalizacji sf-001/cdr/stg/
Dane poprzez przycisk Upload files dodajemy do naszego bucket-u w lokalizacji sf-001/cdr/stg/
Google BigQuery (BQ):
Po zasileniu Cloud Storage udajemy się do usługi BigQuery.
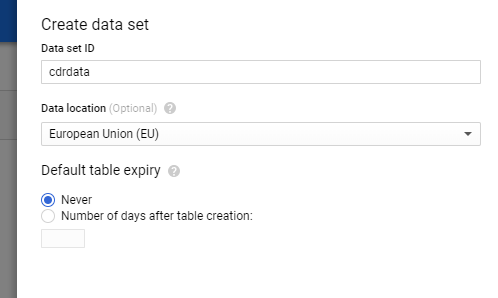
W pierwszej kolejności tworzymy dataset – odpowiada on bazie danych w instancji SQL Server, lub Schematowi w bazie Oracle. Jest więc logicznym pogrupowaniem tabel pod jedną encją.
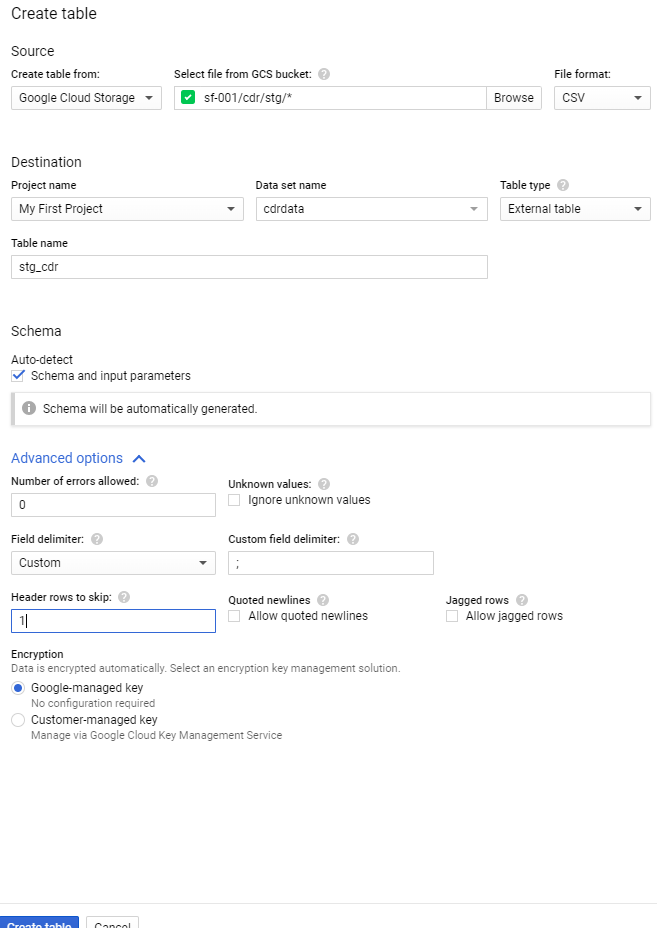
Mając naszą „bazę danych”, możemy utworzyć w niej tabelę, w sekcji Source jest możliwość wybrania do niej źródła danych (tabela może być też pusta), wskazujemy więc nasz bucket na Google Cloud Storage, wildcard * oznacza, że chcemy skorzystać ze wszystkich plików w lokalizacji sf-001/cdr/stg/, format plików to CSV (są również formaty, takie jak AVRO czy Parquet). Określamy, czy tabela ma być native table (fizycznie przechowywana w klastrze ukrytym pod usługą BigQuery) czy external table (tylko logiczna warstwa określająca metadane tabeli). Wybieramy Auto-detect na schemacie tabeli, atrybut Field delimiter „;” oraz, aby pierwszy wiersz (nagłówek) w plikach został pominięty:
Krok 1:
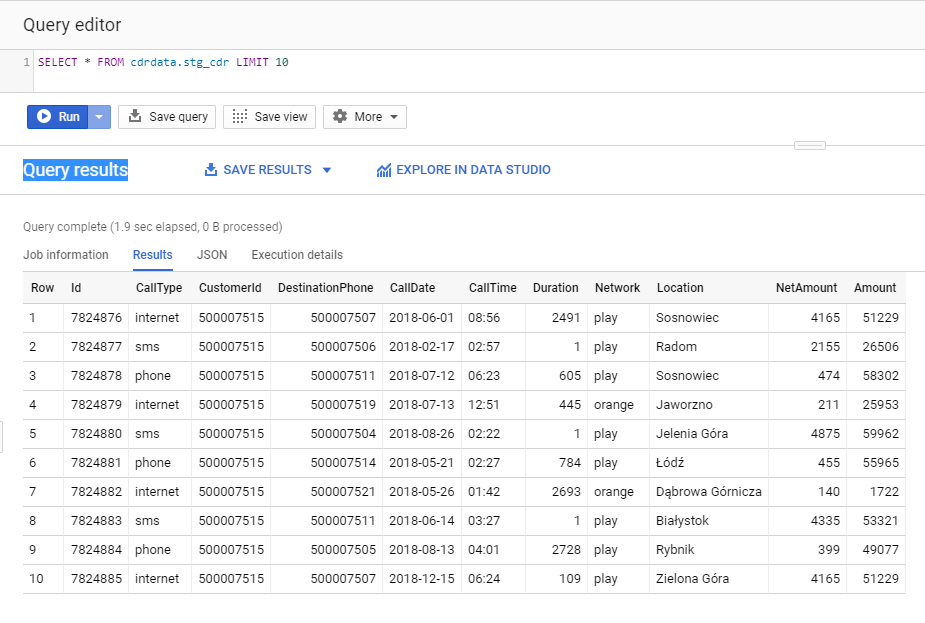
Możemy odpytać utworzoną tabelę:
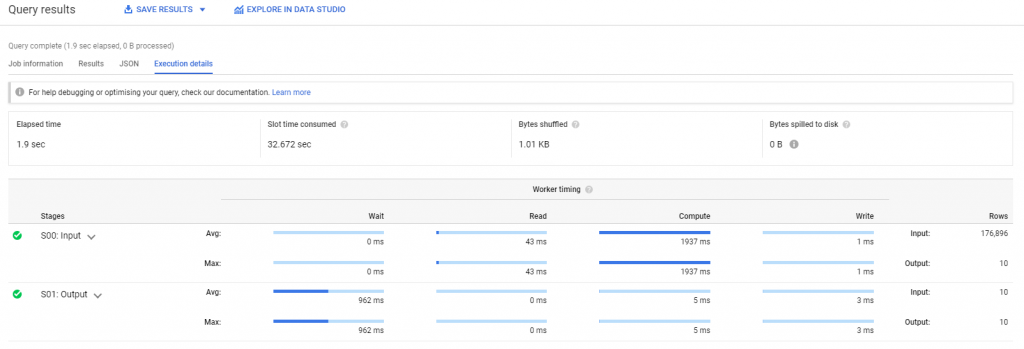
Możemy również obejrzeć coś w rodzaju planu zapytania:
Dokładna liczba rekordów w tabeli:
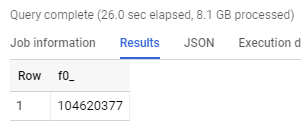
Na tym etapie możemy już skorzystać z danych w raportowaniu jako źródła dla aplikacji lub innych usług Google. Jednak external table nie są tak wydajne, jak native tables, dodatkowo wiemy, że wykryty schemat tabeli nie do końca pokrywa się z tym, czego byśmy oczekiwali.
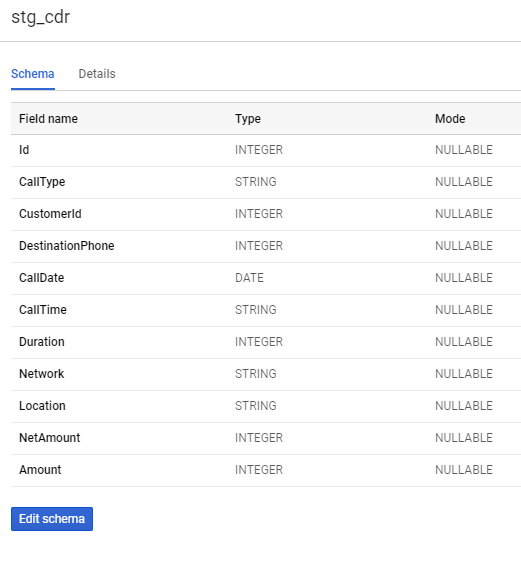
NetAmount , Amount – powinny być liczbami o precyzji 2 miejsc po przecinku, a nie INTEGEREM. Podobnie CallTime powinno być typu TIME. Aby to naprawić utworzymy więc kolejną tabelę typu native:
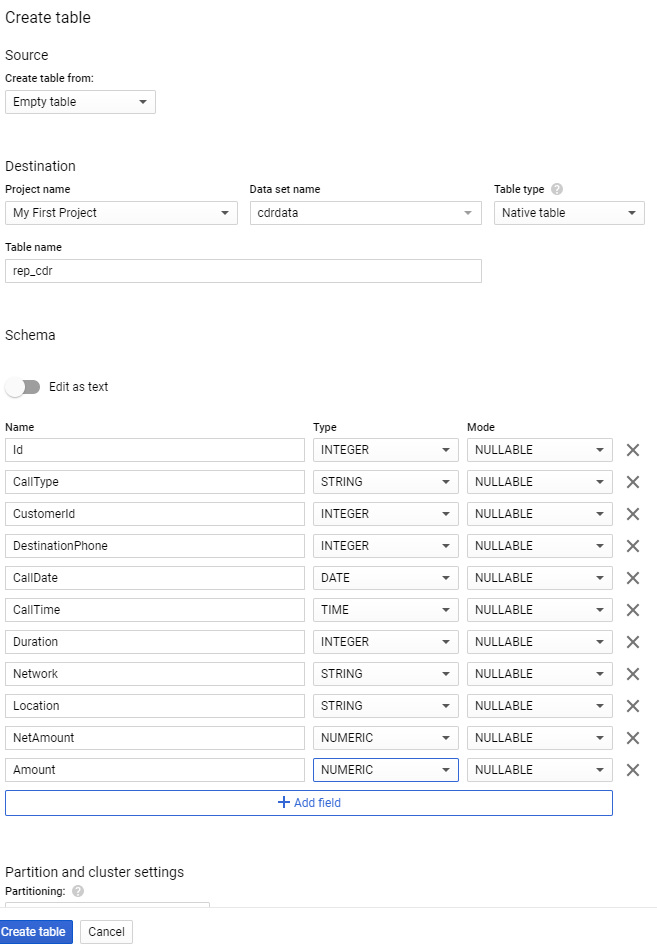
Krok 2:
Następnie wykonamy polecenie SQL:
INSERT INTO cdrdata.rep_cdr(Id, CustomerId, DestinationPhone, CallDate, CallTime,
Duration,Network, Location, NetAmount, Amount, CallType)
SELECT
Id,
CustomerId,
DestinationPhone,
CallDate,
CAST(CONCAT(CallTime,”:00″) AS TIME),
Duration,
Network,
Location,
CAST(NetAmount AS NUMERIC)/100,
CAST(Amount AS NUMERIC)/100,
CallType
FROM cdrdata.stg_cdr
Operacja zakończona sukcesem:
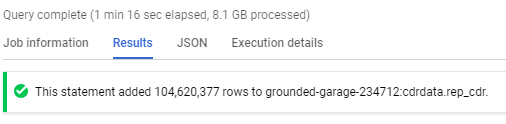
Porównamy teraz wydajność tabel przy prostej agregacji ze zbioru stg_cdr (external table) oraz rep_cdr (native table) na podstawie poniższego zapytania SQL:
SELECT SUM(Duration) NbrOfSms,CustomerId
FROM 'grounded-garage-234712.cdrdata.rep_cdr’
WHERE CallType = 'sms’
GROUP BY CustomerId
ORDER BY 1 DESC LIMIT 100
Oto wyniki odpowiednio stg_cdr i rep_cdr:
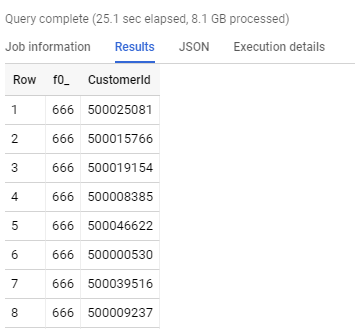
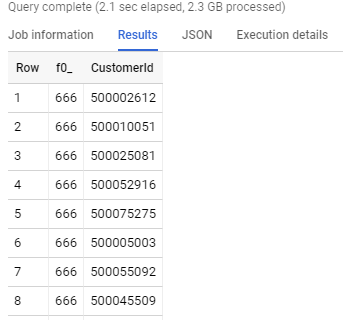
Jak widać na powyższych zdjęciach, zapytanie SQL na native table jest ponad 10x szybsze niż na tabeli external table. Wynika to z faktu, że native table analogicznie jak w Apache Hive (na Apache Hadoop) są przechowywane w formacie kolumnowym i skompresowanym. Dzięki czemu każdy node klastra wykonuje mniejszą ilość operacji i jest w stanie szybciej zwrócić dane.
Na tym etapie na bazie powyższego zapytania dla tabeli rep_cdr możemy również utworzyć widok przy pomocy GUI:
Podsumowanie:
Możemy teraz odpowiedzieć na kilka pytań postawionych na początku:
- Uruchomienie środowiska wraz z rejestracją konta, utworzeniem Cloud Storage oraz tabele BigQuery zajęło 30min – 1h, było intuicyjne i proste. Usługa BigQuery nie ma (w przeciwieństwie do Azure Data Warehouse różnych opcji wydajności usługi) , więc korzystaliśmy z domyślnych opcji przy rejestracji usługi.
- koszt platformy wykorzystanej w trakcie naszych testów wyniósł 0.00zł, nie posiadaliśmy dużo danych, ani nie utworzyliśmy usług na dość długi czas aby Google zdążyło nas obciążyć.
- wydajność BigQuery jest bardzo dobra, usługa skaluje zasoby w zależności od aktualnego obciążenia zapewniając zawsze adekwatne wyniki.
Jak widać wykonanie podstawowych operacji na platformie Google Cloud nie musi być trudne ani czasochłonne. Środowisko zadziwia stabilnością, wydajnością i prostotą. W następnych artykułach pokażemy, jak można wykorzystać polecenia konsolowe gcloud do automatyzacji operacji w ramach Google Cloud. W naszej opinii jest to jedna z lepszych platform na rynku.
Comments are closed.