
Wprowadzenie:
Apache Hadoop jest otwartą platformą programistyczną stworzoną w języku Java. Platforma przeznaczona jest do przetwarzania dużych ilości danych w rozproszonym środowisku, skalowalnym i rozszerzalnym horyzontalnie. Hadoop składa się z wielu komponentów, których podstawą jest HDFS (Hadoop Distributed File System), Hadoop Common (biblioteki używane przez moduły), YARN (Yet Another Resource Negotiator), MapReduce.
W ciągu wielu lat obecności na rynku platforma została rozszerzona o nowe funkcjonalności, obecnie bardzo szeroko używane, takie jak Apache Kafka, Apache Hive, Apache Spark, Apache Flume, Apache Flink. W związku ze zwiększającym się zapotrzebowaniem na skalowalne platformy. Platformy , która pozwala przetwarzać znaczne zbiory danych. Powstały gotowe pakiety instalacyjne zawierające kluczowe funkcjonalności, dostarczają je takie firmy, jak Hortonworks, Cloudera, MapR. W artykule skupimy się na edycji Hortonworks. Pokażemy proces instalacji i konfiguracji klastra składającego sie z 3 nodów (serwerów, węzłów) oraz jednego noda sterującego.
W związku z tym, że platforma zostanie skonfigurowana w chmurze, pierwszym krokiem będzie podjęcie decyzji, której z nich użyć. Mamy do dyspozycji dużych „graczy”, takich jak AWS, Azure, Google oraz mniejsze środowiska, takie jak lokalni dostawcy. My zdecydowaliśmy się na coś pośredniego, mianowicie DigitalOcean.
DigitalOcean oferuje przyjemne, proste i cenowo przystępne środowisko konfiguracji maszyn wirtualnych. Zdecydowaliśmy się na następującą konfigurację:
- 3 maszyny z Ubuntu 16.04 x64, 16GB Ram, 6 vCPU, 320GB za cenę 80$, przeznaczone na nody (węzły klastra)
- 1 maszyna z Ubuntu 16.04 x64, 4GB Ram, 2 vCPU, 80GB za cenę 20$, przeznaczona na komponent sterujący środowiskiem Hadoop
Podsumowując, klaster Hadoop będzie nas kosztował 260 $ miesięcznie, co można uznać za bardzo sensowną cenę, biorąc pod uwagę, że zyskujemy sporą moc obliczeniową oraz możliwość przechowywania znacznych ilości danych w ramach usługi HDFS.
Przygotowanie środowiska:
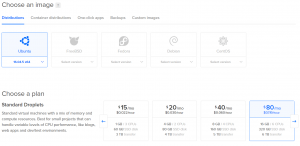
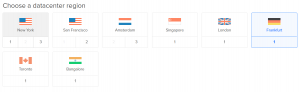
W pierwszej kolejności należy utworzyć maszyny wirtualne, które w DigitalOcean nazywają się „droplets”. Logujemy się więc do panelu sterowania i w prawym górnym rogu wybieramy Create –> Droplets, w Distributions wybieramy Ubuntu 16.04 x64 (na dzień 2019.03.03 edycja Hortonworks zawierała błędy w repozytorium, dlatego nie zdecydowaliśmy się na wersję Ubuntu 18.04.2 x64). Wybieramy parametry serwerów, które nas interesują, lokalizację datacenter region, w naszym przypadku Frankfurt, i wybieramy Create.
Przykładowa konfiguracja poniżej:
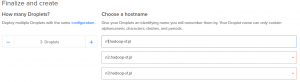
W panelu sterowania powiniśmy zobaczyć podobny obraz jak poniżej:
Dodatkowe ustawienia:
Aby instalacja edycji Hortonworks przebiegła bez problemów należy skonfigurować serwery w taki sposób, aby miały pełną nazwę domenową FDQN, np. myhost.domain.com. W tym celu należy zakupić domenę w dowolnym serwisie, np. Aftermarket.pl i przekierować DNS na serwery DigitalOcean – ns1.digitalocean.com, ns2.digitalocean.com, ns3.digitalocean.com. Po przekierowaniu ruchu z domeny do serwisu DigitalOcean należy ustawić w zakładce Networking–>Domains–>[nazwa domeny] rekordy DNS A, gdzie podajemy Hostname i wybieramy IP dropletu. Od tej chwili ruch zewnętrzny dla nazwy, np. node1.domena.com, będzie kierowany na node1 dropletu w serwisie DigitalOcean.
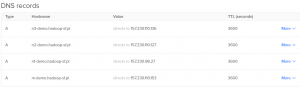
Jak widać z powyższego obrazu nasze maszyny nazywają się odpowiednio:
- nody hadoop: n1–demo.hadoop–sf.pl, n2–demo.hadoop–sf.pl, n3–demo.hadoop–sf.pl
- node sterujący m–demo.hadoop–sf.pl
Należy się teraz zalogować na utworzone droplety w celu:
- zmiany hasła dla użytkownika root (tymczasowe hasło zostanie wysłane na maila wraz z adresem IP). Hasło można zmienić po zalogowaniu się do panelu administracyjnego DigitalOcean i wybraniu Access console, pierwsze logowanie wymaga zmiany hasła tymczasowego z maila.
- zmiany pliku /etc/hostname – ustawić nazwę z rekordów DNS dla odpowiedniego noda
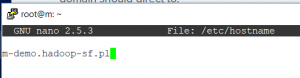
- zmiany pliku /etc/hosts – dodanie IP oraz nazw FDQN wszystkich dropletów w klastrze, oczywiście dla IP 127.0.0.1 nazwy na każdym serwerze będą inne, pozostała część pozostaje jednak bez zmian.
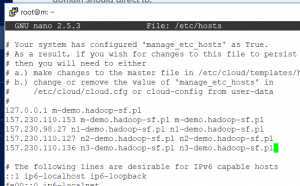
Po wykonaniu powyższych operacji należy zrobić restart wszystkich dropletów, na których zmieniono konfigurację.
Aby instalacja mogła przebiec automatycznie, droplety powinny móc komunikować się między sobą przez SSH, tak więc na droplecie sterującym klastrem należy wygenerować klucz (lub dostarczyć go w inny sposób) poprzez wykonanie komendy ssh–keygen. Polecenie wygeneruje id_rsa.pub w lokalizacji /root/.ssh, plik należy przenieść na wszystkie nody klastra do tej samej lokalizacji – można to zrobić za pomocą narzędzi, takich jak WinSCP. Ostatni krok przed przystąpieniem do instalacji to dodanie klucza publicznego do /root/.ssh/autorized_key na wszystkich dropletach. W celu sprawdzenia poprawności konfiguracji trzeba wykonać połączenie z noda sterującego do pozostalych nodów.
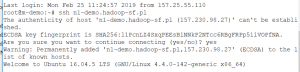
Krok 1:
Instalacja Apache Ambari:
Czym jest Apache Ambari? jest to serwis odpowiedzialny za monitorowanie klastra, pozwalający modyfikować konfigurację, dodawać nowe nody z jednego centralnego punktu architektury. Ambari Agent składa się z 2 komponentów, są to – Ambari Server, instalowany na nodzie sterującym oraz Ambari Agent, instalowany na pozostałych nodach.
Aby zainstalować na Ubuntu 16.04 x64 Ambari Server/Agent należy wykonać na wszystkich nodach poniższe polecenia:
wget –O /etc/apt/sources.list.d/ambari.list http://public–repo–1.hortonworks.com/ambari/ubuntu16/2.x/updates/2.7.3.0/ambari.list
apt–key adv ––recv–keys ––keyserver keyserver.ubuntu.com B9733A7A07513CAD
apt–get update
apt–cache showpkg ambari–server
apt–cache showpkg ambari–agent
apt–cache showpkg ambari–metrics–assemblyNa serwerze sterującym instalujemy Ambari Server, wykonując polecenia:
apt–get install ambari–server
ambari–server setupOstatnie polecenie uruchamia konfigurację serwera:
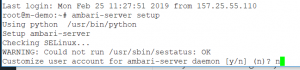
Jeżeli nie chcemy używać innych kont poza root na serwerze – wtedy powinniśmy wybrać „n”, w przeciwnym wypadku należy stworzyć odpowiednie konta przed procesem instalacji.

Jak wspomnieliśmy Apache Hadoop bazuje na języku Java – razem z instalacją należy więc zadbać o odpowiednią wersję JDK, domyślnie jest to Oracle JDK 1.8, w tym miejscu można wskazać również inną wersję, wybierając „2”

Należy wyrazić zgodnę na zapisy licencji Oracle – wybieramy „y”.

Trzeba również zaakceptować licencję GPL – wybieramy „y”.

Apache Ambari może funkcjonować na różnych bazach danych, domyślnie jest to PostgreSQL na instacji localhost. Można wskazać jednak inną bazę i inną lokalizację – wybieramy „n”.
Instalacja zakończona!
Krok 2:
Po konfiguracji uruchamiamy serwer
ambari–server startNa pozostałych nodach wykonujemy polecenia
apt–get install ambari–agent
ambari–agent startMamy już zainstalowany główny komponent, pozwalający nam na wszystkich nodach klastra zachować spójną instalację i konfigurację. Aby jednak odbyła się ona bez ingerencji, należy zadbać jeszcze o dodatkowe komponenty, takie jak biblioteki JAR czy bazy danych. Podstawową bazą danych, używaną przez większość komponentów Hadoop, jest MySQL.
Instalujemy ją więc na wszystkich nodach:
sudo apt–get install mysql–server
systemctl status mysqlA na nodzie sterującym instalujemy i konfigurujemy bibliotekę JAR dla MySQL
sudo apt–get install libmysql–java
sudo ambari–server setup ––jdbc–db=mysql ––jdbc–driver=/usr/share/java/mysql.jarAby dopełnić przygotowanie środowiska, musimy jeszcze zadbać o dwie rzeczy, pierwszą z nich jest serwis NTP odpowiedzialny za synchronizację czasów między serwerami – istotny komponent w przypadku rozproszonego środowiska, którego nody regularnie komunikują się między sobą po protokole TCP/IP.
apt–get install ntp
update–rc.d ntp defaults
service ntp startOstatnia rzecz to możliwość komunikacji pomiędzy zainstalowanymi w przyszłości usługami. Każda usługa Hadoop komunikuje się po 1 lub wielu portach. Na czas tej instalacji, aby uniknąć listowania wszystkich portów dla usług, które zainstalujemy. Firewall wyłączony, aby zapewnić otwartą komunikację między nimi. Uwaga, w produkcyjnej instalacji należy wylistować porty i zadecydować samemu. Na których z nich usługi mają działać, nie należy pozostawiać nieaktywnych zabezpieczeń).
sudo ufw disable
sudo iptables –X
sudo iptables –t nat –F
sudo iptables –t nat –X
sudo iptables –t mangle –F
sudo iptables –t mangle –X
sudo iptables –P INPUT ACCEPT
sudo iptables –P FORWARD ACCEPT
sudo iptables –P OUTPUT ACCEPT
Krok 3:
Instalacja Apache Hadoop przy pomocy Apache Ambari:
Aby zalogować się do Apache Ambari, należy wpisać nazwę noda sterującego (z zainstalowanym Apache Ambari Server) w przeglądarce, serwer działa na porcie 8080
http://m–demo.hadoop–sf.pl:8080Użytkownik i hasło domyślne to: admin/admin
Po zalogowaniu się należy uruchomić Install Wizard
Wybieramy nazwę naszego klastra
Na następnej stronie, po wybraniu Next, pojawi się lista repozytoriów, z których będziemy korzystać podczas instalacji. Jest także możliwość wybrania edycji Hortonworks – wybieramy HDP 3.1 z Use Public Repository
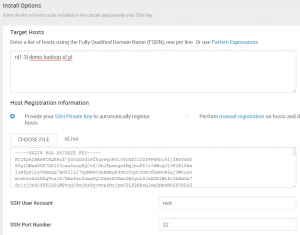
Po wciśnieciu Next możemy wybrać nody wchodzące w skład naszego klastra oraz wskazać klucz publiczny. Przy pomocy którego Apache Ambari będzie łączył się poprzez SSH do nodów klastra z noda sterującego.
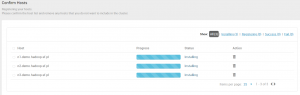
Na kolejnym ekranie widać postęp rejestracji Apache Ambari na nodach klastra. W przypadku wystąpienia problemów z łącznością SSH lub otwarciem portów na nodach otrzymamy komunikat oraz informację w logu na temat przyczyny błędu.
Wybraliśmy elementy, które zostaną zainstalowane w ramach naszego klastra.
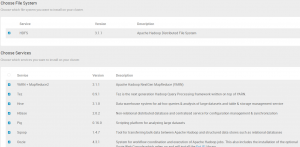
Nie wszystkie są niezbędne, my zdecydowaliśmy się na poniższą listę:
HDFS, YARN+MapReduce2, Tez, Hive, Spark2, HBase, Pig, Sqoop, Zookeeper, Ambari Metrics, Kafka, Zeppelin Notebook.
Krok 4:
Oczywiście inne komponenty również mogą zostać wybrane. W przypadku ich braku na liście można później je doinstalować z poziomu terminala bądź znaleźć moduł rozszerzający funkcjonalność Apache Ambari o wspomniany komponent.
Na następnym ekranie widzimy komponenty zainstalowane na nodach. Jest to dość istotny krok, ponieważ dobre przemyślenie architektury i lokalizacji komponentów pozwoli nam na poprawną optymalizację oraz równe obciążenie nodów.
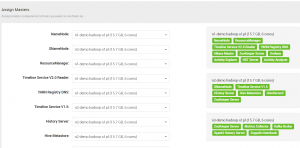
W następnym kroku uzupełniamy powyższą listę.
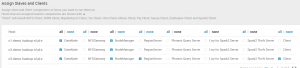
Istotne jest, aby wybrać jak największą liczę nodów z DataNode i NodeManager, gdyż umożliwia to lepsze rozproszenie procesów i danych w ramach naszego klastra.
W kolejnym kroku ustawiamy uprawnienia użytkowników, z których będą korzystać usługi w naszym klastrze.
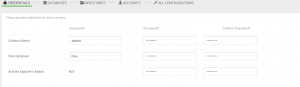
Wpisujemy uprawnienia użytkowników do baz danych – dodam tutaj, że należy stworzyć użytkowników i bazy danych w instacji MySQL (lub innych baz danych) przed wykonaniem instalacji Apache Ambari.
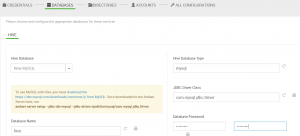
Katalogi, w których będą zainstalowane komponenty Apache Hadoop pozostawiamy bez zmian, konta również. Całość konfiguracji każdego z komponentów można obejrzeć w ostatniej zakładce – pozostawiamy je domyślne.
W kolejnym ekranie mamy podsumowanie naszych wyborów wraz z możliwością wygenerowania szablonu GENERATE BLUEPRINT w przypadku, kiedy nasza instalacja będzie powtarzalna.
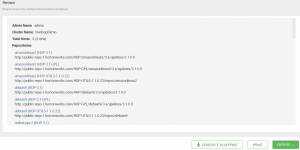
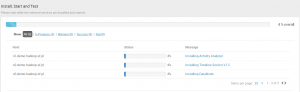
Klikamy DEPLOY i obserwujemy proces instalacji. W razie wystapienia błędów instalacja przerwie się z odpowiednim komunikatem w logu, można ją jednak wznowić po ich naprawieniu.
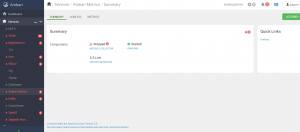
Instalacja zostaje zakończona, poniżej panel administracyjny Apache Ambari po zakończeniu instalacji
Podsumowanie:
Jak widać proces instalacji nie jest trudny, nie wymaga specjalnych umiejętności i przy użyciu gotowych edycji, takich jak np. Hortonworks może zostać zakończony w ciągu 2–3 h w przypadku 3–nodowego klastra z jednym nodem sterującym. Trzeba jednak zaznaczyć, że instalacja jest tylko jednym z elementów poprawnej konfiguracji Apache Hadoop. Każda z usług wymaga indywidualnego podejścia i wypracowania metodyki i optymalizacji. Należy także poprawnie zaprojektować klaster. Jedną z podstawowych zalet Apache Hadoop jest jego szeroka dostępność i rozproszenie pracy na wiele nodów. Aby jednak awaria jednego noda nie wpłyneła na aktualnie wykonywane procesy – należy odpowiednio propagować usługi na dostępne nody. W kolejnych artykułach postaramy się opisać nasze doświadczenia w zakresie optymalizacji Hadoop w kontekście używania Hive i Spark.