
Wprowadzenie:
Przed Wami kolejny z serii artykułów poświęconych analizie środowisk w chmurze, takich jak Google, AWS, Azure pod kontem użyteczności w obróbce danych.
Skupimy się w nim na środowisku Azure, a konkretnie na Azure Data Warehouse i usłudze Azure Storage wykorzystanej w celu analizy plików CDR (call detail record), (podobnie jak w poprzednim artykule dotyczącym środowiska Google).
Postaramy się odpowiedzieć na pytania:
- jak trudno jest utworzyć środowisko pozwalające procesować pliki CDR (struktura opisana poniżej) ze 100 mln rekordów,
- jaki jest koszt platformy wykorzystywanej w trakcie naszego testu,
- jaka jest wydajność platformy
Use Case:
Jako przykład użycia wybraliśmy przetwarzanie plików zwanych CDR, czyli call detail record. Są to pliki często wykorzystywane w branży telekomunikacyjnej. Ich formaty mogą być najróżniejsze, nie ma też jednego przyjętego standardu. Na potrzeby tego przykładu przygotowaliśmy następujący format plików:
Id INT, CustomerId INT, DestinationPhone INT, CallDate DATE, CallTime STRING, Duration INT, Network STRING, Location STRING, NetAmount NUMBER, Amount NUMBER – NetAmount i Amount są przechowywane w pliku źródłowym jako INT, jednak odpowiadają liczbie o precyzji 2 miejsc po przecinku, np. 101 oznacza 1.01.
Przykładowe dane:

Przeprowadzimy na nich proste agregacje w celu sprawdzenia wydajności środowiska i oszacowania, jak skomplikowane będzie wdrożenie nowej platformy. Azure Data Warehouse jest pomysłem Microsoftu na zaimplementowanie koncepcji rozproszonej bazy danych, analogicznej do Teradata. Aplikuje ona MPP – massive parallel processing. Architektura rozwiązania składa się z compute nodów (ich liczba zależy od poziomu usługi wybranej w panelu Azure – od 1 do 60) oraz jednego control noda. Warstwą do przechowywania danych jest Azure Storage.
Każde zapytanie SQL wysłane do control node zostanie zamienione na mniejsze zadania dystrybuowane między dostępne compute nody. W przypadku, kiedy zaistnieje konieczność przeniesienia danych między nimi (np. kiedy jest różna dystrybucja danych w dwóch tabelach łączonych) uruchamia się usługa DMS (Data Movement Service).
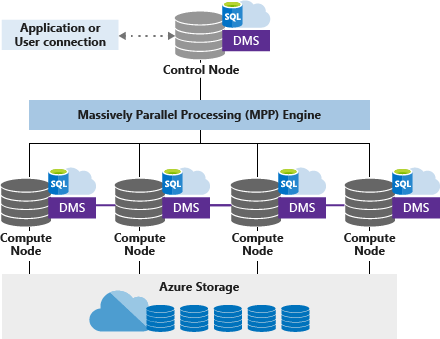
https://docs.microsoft.com/pl-pl/azure/sql-data-warehouse/massively-parallel-processing-mpp-architecture
Azure Storage – a konkretnie blob storage używany w naszym przykładzie – jest usługą rozproszonego przechowywania plików analogiczną do Hadoop HDFS bądź Google Cloud Storage. Dystrybucja plików między wieloma dostępnymi serwerami zapewnia ich bezpieczeństwo (pliki są replikowane na różne zasoby), szybkość (czytanie odbywa się z wielu źródeł jednocześnie), pojemność, dystrybucję danych między lokalizacjami.
Pierwsze kroki:
Aby zacząć naszą przygodę z platformą Azure należy założyć konto – i tutaj mamy dobrą wiadomość – Microsoft pozwala nam utworzyć darmowe konto próbne na 30 dni ze 170 EUR do wykorzystania we wszystkich usługach, jakie oferuje platforma Azure.

W celu skorzystania z oferty należy wypełnić dane osoby prywatnej badź firmy oraz dane billingowe. Po udanej rejestracji możemy przystąpić do uruchamiania usług – logujemy się więc na adres panelu sterowania. Następnie należy w naszej subskrypcji stworzyć grupę zasobów – naszą nazwaliśmy Demo:
Azure Storage:
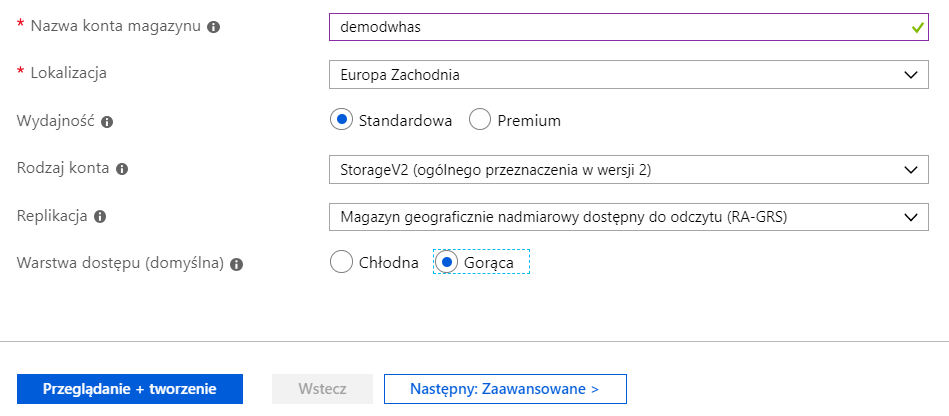
Aby ustawić usługę Azure Storage należy z menu wybrać konta magazynu, a następnie Utwórz konto magazynu. Ponieważ nasz przykład nie wymaga specjalnych ustawień, wskazaliśmy konfigurację konta demodwhas na podstawie poniższych parametrów. Istotna jest jednak lokalizacja (w kontekście przechowywania np. danych osobowych), replikacja oraz wartswa dostępu – w celu uzyskania najlepszej wydajności wybieramy Gorąca (Hot).
Panel zarządzania kontem magazynu wygląda następująco:
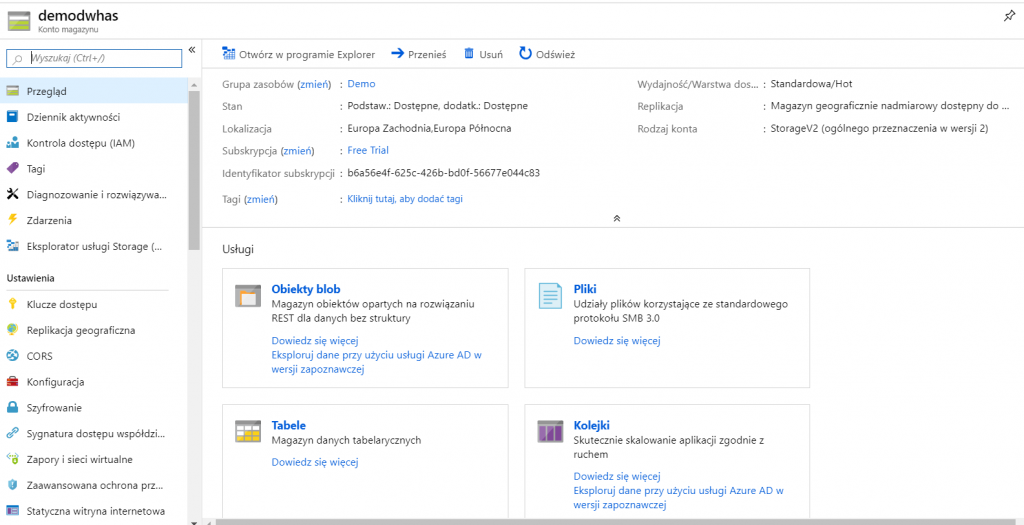
Interesuje nas sekcja Obiekty blob – to tam będziemy przechowywać nasze pliki z danymi przed załadowaniem ich przy pomocy Polybase do usługi Azure Data Warehouse.
W celu wydzielenia odpowiednich zasobów na nasze pliki w magazynie danych należy stworzyć kontener:
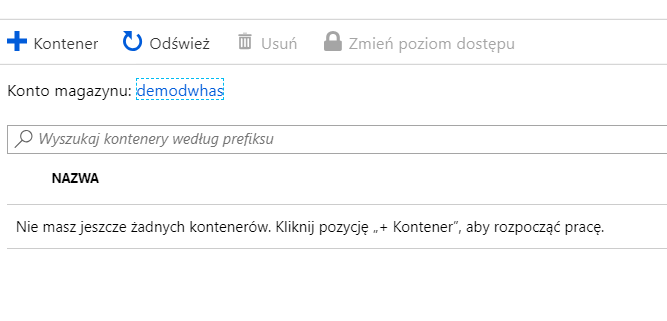
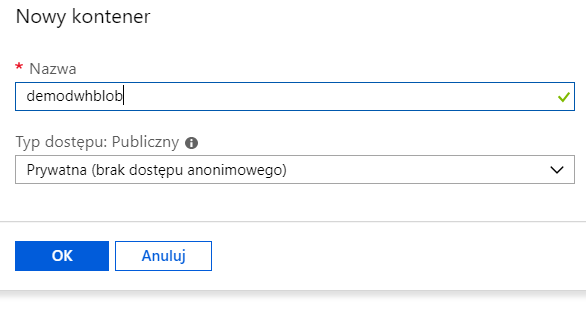

Microsoft opracował wygodne narzędzie do zarządzania danymi znajdującymi się w Azure Storage – jest to Azure Storage Explorer, którego można pobrać za darmo ze strony Microsoft:
Aplikacja po zainstalowaniu wygląda następująco:
Na marginesie – Microsoft oferuje również narzędzia command line, takie jak AzCopy dostępne w środowisku Windows oraz Linux w celu automatyzacji operacji wysyłania i odbierania plików z Azure Storage.
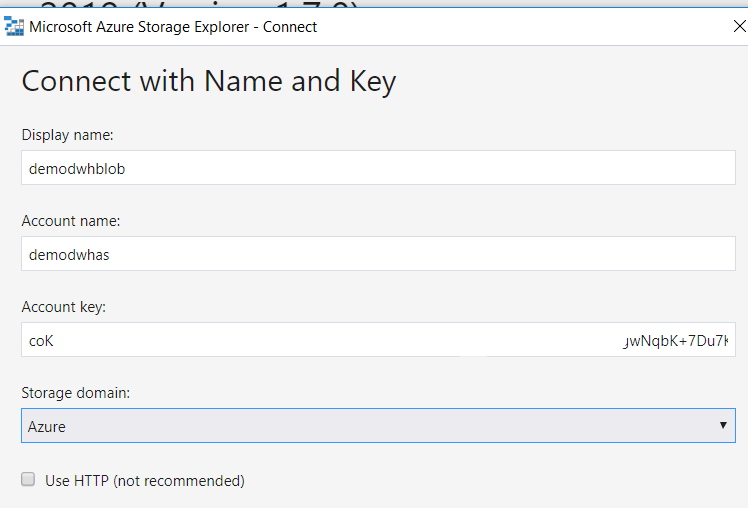
Aplikacja Azure Storage Explorer posłuży nam do załadowania plików do usługi Azure Storage, w tym celu musimy połączyć aplikację do konta magazynu. Można to zrobić na kilka sposobów, najprościej jednak będzie – przy pomocy nazwy konta oraz klucza do usługi. Nazwa konta to wcześniej utworzone konto magazynu, czyli demodwhas, klucz znajduje się w danych kontenera obiektu blob, jest to unikalny, długi, składający się z dużej liczby losowych znaków tekst.
Przykład konfiguracji poniżej:
W ramach Azure Blob Storage możemy tworzyć katalogi:
A do utworzonego katalogu możemy „przeciągnąć” pliki z lokalnego katalogu:
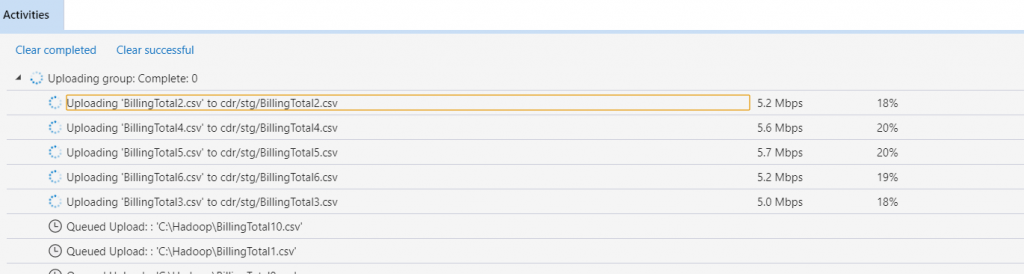
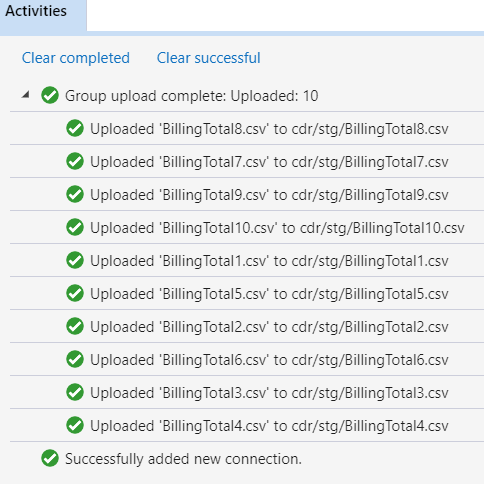
Gdy mamy już zasiloną usługę Azure Storage, możemy przejść do utworzenia Azure Data Warehouse.
Data Warehouse:
Aby móc korzystać z Azure Data Warehouse, należy najpierw utworzyć serwer Data Warehouse, gdzie będzie zlokalizowana baza danych, na której będziemy wykonywać testy. W tym celu w menu po lewej stronie wybieramy Utwórz zasób i w pasku wyszukiwania wpisujemy Data Warehouse. Otrzymujemy poniższy szablon:
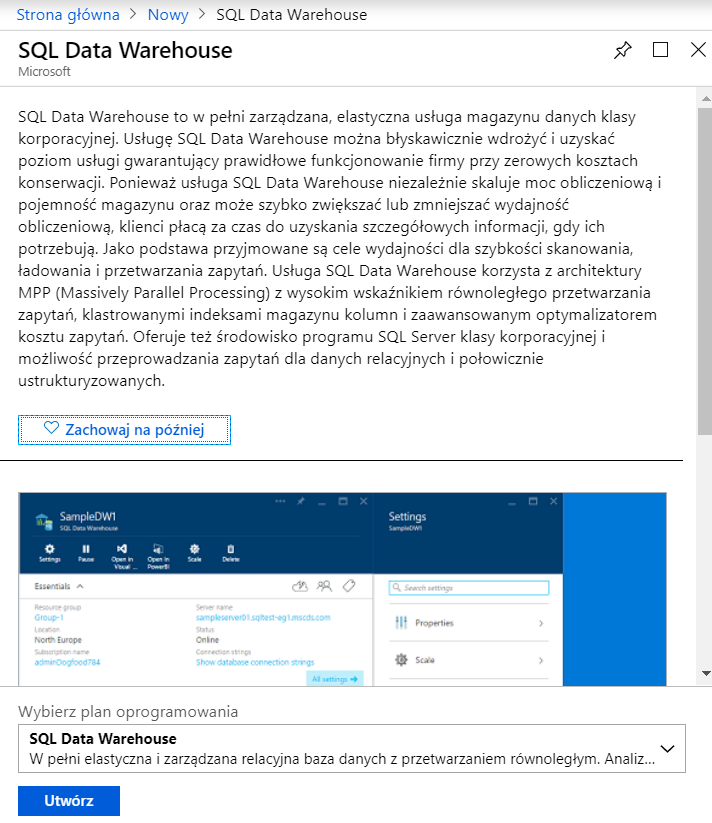
Uzupełniamy informacje niezbędne do utworzenia instancji SQL, czyli nazwę bazy danych, poziom wydajności, lokalizację oraz nazwę serwera, na którym zostanie utworzona baza danych (oczywiście istotne jest też, w jakiej subskrypcji i grupie zasobów ona będzie).
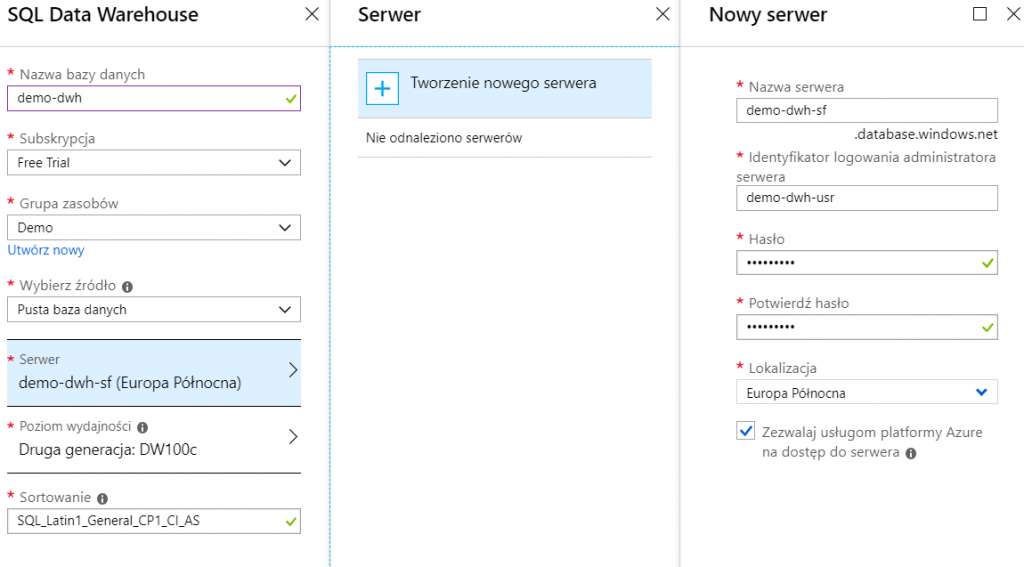
Po upłynięciu kilku, kilkunastu minut zostanie utworzony serwer wraz z bazą danych:
Aby móc podłączyć się do utworzonej instacji, należy wybrać w panelu usługi ustawienia zapory:
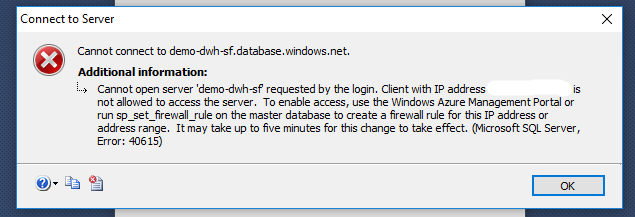
Następnie trzeba dodać IP naszej lokalizacji, w przeciwnym wypadku otrzymamy następujący błąd w aplikacji SQL Server Management Studio:
Dane połączenia znajdziemy w panelu usługi, podczas tworzenia zasobu podawaliśmy również nazwę i hasło użytkownika, który jest naszym superuserem i dzięki któremu możemy tworzyć innych użytkowników i zarządzać instancją. Aby móc się zalogować i poprawnie obsługiwać wszystkie funkcje Data Warehouse, musimy mieć SQL Server Management Studio w wersji wyższej lub równej 17.0.
Drzewo funkcji w Solution Explorer jest nieznacznie inne niż w standardowej edycji SQL Server i wygląda następująco:
Trochę kodu:
Mamy więc gotowy serwer Data Warehouse wraz z bazą danych i danymi w środowisku chmury Azure.
Aby z poziomu SQL można było skorzystać z danych znajdujących się na Azure Storage, należy wykonać kilka wstępnych zapytań SQL oraz utworzyć master key dla bazy:
CREATE MASTER KEY;
Trzeba też stworzyć obiekt uprawnień dla użytkownika, który będzie przechowywał klucz usługi Azure Storage.
CREATE DATABASE SCOPED CREDENTIAL BlobCred
WITH
IDENTITY = 'demo-dwh-usr’,
SECRET = '<azure_storage_key>’;
Należy utworzyć obiekt wiążący konto Azure Storage i uprawnienia opisane powyżej.
CREATE EXTERNAL DATA SOURCE DemoBlob
WITH
(
TYPE = Hadoop,
LOCATION = 'wasbs://[email protected]’,
CREDENTIAL = BlobCred
);
Musimy również zdefiniować format pliku, który będziemy czytać przy pomocy Data Warehouse. Plik zawiera nagłówki, więc pierwsza linia z danymi to 2, separatorem jest „;” a plik ma ograniczoną strukturę ze zmienną liczbą znaków w rekordzie.
CREATE EXTERNAL FILE FORMAT CSVFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS
(
FIELD_TERMINATOR = ’;’,
USE_TYPE_DEFAULT = FALSE,
FIRST_ROW = 2
)
);
W celu odseparowania tabel zewnętrznych (wyjaśnienie poniżej) od tabel przechowywanych na serwerze SQL tworzymy dwa schematy:
CREATE SCHEMA ext;
CREATE SCHEMA stg;
Trochę więcej kodu:
Wróćmy do pojęcia tabeli zewnętrznej. Microsoft w wersjach SQL Server 2016 wprowadził narzędzie zwane Polybase, była to ich własna implementacja koncepcji Hadoop Hive lub Google BigQuery – external table. Pozwala na czytanie plików z zasobu/źródła rozproszonego również w sposób rozproszony (wielowątkowo, na więcej niż jednej maszynie). Microsoft wprowadził także nową składnię w poleceniu CREATE TABLE -> CREATE EXTERNAL TABLE. Tabele te nie są zmaterializowane i są czytane AdHoc (a właściwie czytane są pliki) w momencie wykonania zapytania SELECT. Nowe narzędzie pozwoliło zwiększyć prędkość i wydajność czytania dużej liczby plików, kierując się bardziej w stronę ELT (extract-load-transform) zamiast ETL.
Utwórzmy więc naszą pierwszą tabelę zewnętrzną:
CREATE EXTERNAL TABLE [ext].[cdr](
Id INT,
CallType VARCHAR(25),
CustomerId INT,
DestinationPhone INT,
CallDate VARCHAR(30),
CallTime VARCHAR(10),
Duration INT,
Network VARCHAR(25),
Location VARCHAR(25),
NetAmount VARCHAR(30),
Amount VARCHAR(30)
)
WITH (LOCATION=’/cdr/stg/’,
DATA_SOURCE = DemoBlob,
FILE_FORMAT = CSVFormat,
REJECT_TYPE = VALUE,
REJECT_VALUE = 0
);
Utworzymy tabelę o logicznej strukturze opisanej powyżej, ale z danymi w plikach płaskich znajdujących się w lokalizacji /cdr/stg/, opisanych formatem CSVFormat na Azure Storage wskazanym w obiekcie DemoBlob.
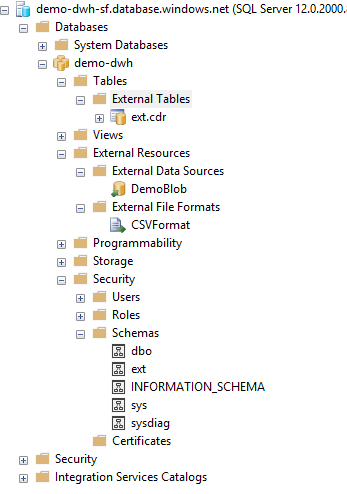
Przykład drzewa obiektów po wykonaniu powyższych operacji:
Testujemy:
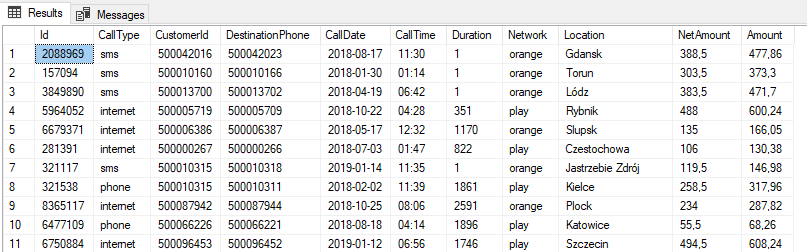
Wykonajmy zapytanie:
SELECT TOP 100 * FROM [ext].[cdr]
Wynik i czas zapytania:

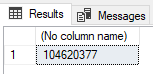
SELECT COUNT(*) FROM [ext].[cdr]

Sprawdźmy teraz, w jaki sposób możemy zmaterializować dane w instancji SQL przy pomocy zwykłych tabel SQL:
CREATE TABLE [stg].[cdr]
WITH
(
DISTRIBUTION = HASH(Id)
, CLUSTERED COLUMNSTORE INDEX
)
AS
SELECT
[Id],
[CallType],
[CustomerId],
[DestinationPhone],
CAST([CallDate] AS DATE) [CallDate],
CAST([CallTime] AS TIME(0)) [CallTime],
[Duration],
[Network],
[Location],
CAST(REPLACE([NetAmount],’,’,’.’) AS DECIMAL(18,2)) [NetAmount],
CAST(REPLACE([Amount],’,’,’.’) AS DECIMAL(18,2)) [Amount]
FROM ext.cdr
Korzystamy z CTAS – Create Table As Select, czyli tworzymy tabelę „w locie”. Metadane tabeli są wnioskowane na podstawie typów danych zwróconych w SELECT. W tym miejscu mamy też możliwość wykonać proste operacje CAST bądź REPLACE w celu transformacji danych załadowanych do Azure Storage (zastosowanie podjeścia ELT). Jedne z bardziej istotnych pozycji w zapytaniu to DISTRIBUTION = HASH(Id) , czyli rodzaj dystrybucji danych (mamy jeszcze do dyspozycji ROUND_ROBIN – czyli losowa dystrybucja, oraz REPLICATED, czyli każdy compute node ma zreplikowane dane). Drugą istotną pozycją jest CLUSTERED COLUMNSTORE INDEX – określa on typ przechowywania danych w tabeli, jak można się domyślić w tym przypadku mamy do czynienia z przechowywaniem w postaci kolumnowej, mamy jeszcze możliwość użycia HEAP, czyli przechowujemy tabele w sposób standardowy – wierszowy.
Czas wykonania zapytania SQL CTAS:

Sprawdźmy wydajność nowej tabeli:
SELECT COUNT(*) FROM [stg].[cdr]

Proces agregacji jest znacznie krótszy w porównaniu do COUNT(*) na tabeli zewnętrznej
Wykonajmy również dwa poniższe zapytania agregujące, jedno na tabeli zmaterializowanej, a drugie na tabeli zewnętrznej:
SELECT TOP 100 SUM(Duration) NbrOfSms,CustomerId
FROM stg.cdr
WHERE CallType = 'sms’
GROUP BY CustomerId
ORDER BY 1 DESC
SELECT TOP 100 SUM(Duration) NbrOfSms,CustomerId
FROM ext.cdr
WHERE CallType = 'sms’
GROUP BY CustomerId
ORDER BY 1 DESC
Odpowiednio wyniki i wydajność:


Jak widać różnica w czasie wykonania zapytania jest znacząca.
Podsumowanie:
Odpowiedzmy sobie na pytania postawione na początku artykułu
- utworzenie środowiska jest proste i nie wymaga znacznej wiedzy technicznej, podstawowe środowisko pozwalające nam na utworzenie pierwszych tabel czy zapytań agregujących wymaga 1-1,5 h czasu.
- koszt platformy jest niewielki < 10 EUR, jednak trzeba zaznaczyć, że billing w platformie Azure nie jest tak przejrzysty, jak w innych usługach chmurowych. Microsoft potrafi obciążać kosztami za usługi, z których już nie korzystamy – jest tak np. z Azure Storage, gdzie mimo skasowania danych przez 7 następnych dni opłata za usługę jest pobierana. Trzeba mieć również na uwadze, że w SQL Data Warehouse także niejawnie płacimy za storage, co w praktyce daje zdublowany rachunek za usługę.
- aby koszt był jak najniższy, skorzystaliśmy z minimalnych ustawień Data Warehouse DW100c, w celu uzyskania zadowalającej wydajności najlepiej przejść do usług DW1000c – jednak to powoduje znaczny wzrost kosztów. Wydajność usługi jest mniejsza niż innych rozwiązań chmurowych, które prezentowaliśmy i będziemy prezentować.
Niewątpliwą zaletą korzystania z platformy Microsoft Azure jest jej szybki rozwój w ciągu ostatnich lat, a także dostępna mnogość funkcji i opcji. Platforma wymaga jednak jeszcze pracy w obszarach stabilności i przejrzystego billingowania. Jej prostota w użytkowaniu ma również duże znaczenie, wymieniony wyżej Azure Data Warehouse korzysta z narzędzi dobrze już znanych każdemu deweloperowi BI, który miał styczność z Microsoft SQL Server. W tym zakresie Microsoft wyprzedza konkurencję. Koszt adaptacji dewelopera do nowego środowiska będzie więc minimalny.
Comments are closed.